
{kind=link}

Let’s get movies from IMDb using Cheerio and save the data in the Mysql database using Sequelize.
I thought that it would be a good practice to create a movie app using Node.js but the biggest challenge is to get all this amount of data. So web scraping is our best method to get the data from a public website such as IMDB.
We will create a RESTful API app using Express.js and Cheerio for web scraping and Sequeliz to save the data in the MYSQL database for practice. Let’s get started.
Creating Web Scrapping application
We will use Express framework for our application. Let’s create the application and install the dependencies
$ npx express-generator
$ cd myapp
$ npm installLet’s install Nodemon to monitor any change in the script and reload the development server automatically.
npm i nodemonLet’s install Sequelize, the Node.js ORM for Oracle, Postgres, MySQL, MariaDB, SQLite SQL Server, and more.
npm install --save sequelizeFinally, for now, let’s install the CLI of Sequelize.
npm install --save-dev sequelize-cliLet’s initialize our application to start using our database, I suppose you already have a MySQL database installed.
npx sequelize-cli initThis will create the following folders:
config, Contains a configuration file that tells the CLI how to connect to the database.models, Contains all of the models for your project.migrations, Contains all of the migration files.seeders, Contains all of the seeder files.
But before we continue with our database we need to add these scripts in package.json file so we can use them quickly.
"scripts": {
"start": "node ./bin/www",
"dev": "nodemon index.js",
"migrate" : "npx sequelize-cli db:migrate"
},Now to run the development server all we have to do is write this command in the terminal npm run dev , and we do the same thing with the migration.
Let’s add our database connection data config/config.json so have multiple databases, we will use the development one.
{
"development": {
"username": "root",
"password": "Password",
"database": "node_sq",
"host": "127.0.0.1",
"dialect": "mysql"
},
"test": {
"username": "root",
"password": Password,
"database": "node_sq",
"host": "127.0.0.1",
"dialect": "mysql"
},
"production": {
"username": "root",
"password": "Password",
"database": "node_sq",
"host": "127.0.0.1",
"dialect": "mysql"
}
}
Let’s connect our database, create a new file config/db.js , and add the following code.
const { Sequelize } = require('sequelize');
const { sequelize } = require('../models');
// this function to sync the tables or table changes in the databese
async function main(){
//await sequelize.sync({alter:true});
}
main();The main function is for synchronizing the tables or table changes in the database. It is up to you to use it or not. I recommend using migration instead. We need to add our database configuration to app.js to connect the database once the server is started.
const sequelize = require('./config/db');Let’s create our first table to save the movie data that will get from IMDb. we can use Sequelize-cli to generate the model and migration files.
npx sequelize-cli model:generate --name Movie --attributes name:string,description:string,poster:stringGo to migrations/20231128122158-create-movie.js (date is different) and add some more columns adjust the id column as the following code and make sure the move name is unique.
'use strict';
/** @type {import('sequelize-cli').Migration} */
module.exports = {
async up(queryInterface, Sequelize) {
await queryInterface.createTable('Movies', {
id: {
allowNull: false,
autoIncrement: true,
primaryKey: true,
type: Sequelize.INTEGER
},
name: {
type: Sequelize.STRING,
unique: true,
},
description: {
type: Sequelize.TEXT
},
poster: {
type: Sequelize.STRING
},
year: {
type: Sequelize.INTEGER
},
runtime: {
type: Sequelize.INTEGER
},
vote: {
type: Sequelize.INTEGER
},
genre: {
type: Sequelize.STRING
},
rate: {
type: Sequelize.FLOAT
},
gross: {
type: Sequelize.STRING
},
certificate: {
type: Sequelize.STRING
},
cast: {
type: Sequelize.JSON
},
createdAt: {
allowNull: false,
type: Sequelize.DATE
},
updatedAt: {
allowNull: false,
type: Sequelize.DATE
}
});
},
async down(queryInterface, Sequelize) {
await queryInterface.dropTable('Movies');
}
};Let’s do the same thing for models/movie.js
'use strict';
const {
Model
} = require('sequelize');
module.exports = (sequelize, DataTypes) => {
class Movie extends Model {
/**
* Helper method for defining associations.
* This method is not a part of Sequelize lifecycle.
* The `models/index` file will call this method automatically.
*/
static associate(models) {
// define association here
}
}
Movie.init({
id: {
allowNull: false,
type: DataTypes.INTEGER,
autoIncrement: true,
primaryKey: true
},
name:{
type: DataTypes.STRING,
allowNull:false,
},
year:{
type: DataTypes.INTEGER,
allowNull:true,
},
poster:{
type: DataTypes.STRING,
allowNull:true,
},
description:{
type: DataTypes.TEXT,
allowNull:false,
},
runtime:{
type: DataTypes.INTEGER,
allowNull:true,
validate: {
isInt: true,
},
},
genre:{
type: DataTypes.STRING,
allowNull:false,
},
rate:{
type: DataTypes.FLOAT,
defaultValue: 0,
validate: {
isNumeric: true,
},
},
vote:{
type: DataTypes.INTEGER,
defaultValue: 0,
validate: {
isInt: true,
},
},
certificate:{
type: DataTypes.STRING,
allowNull:true,
},
cast:{
type: DataTypes.JSON,
allowNull:true,
},
gross:{
type: DataTypes.STRING,
allowNull:true,
},
}, {
sequelize,
modelName: 'Movie',
});
return Movie;
};Let’s migrate our table
npm run migrateNow, our table should be created in the database.
Creating Cheerio Service for Web Scrapping.
Fun time, let’s install Cheerio and Axios so that we can get the web pages and scrap the data from them.
npm install cheerionpm install axiosWe need to add routes and controllers before creating the service modules first, the route will have a prefix movies. Let’s add the below code in “app.js” file
//
app.use(express.static(path.join(__dirname, 'public')));
//adding the movies route
var moviesRouter = require('./routes/movies');
app.use('/movies', moviesRouter);
//Let’s create routes/movies.js a route file and add the movie controller that we will create in the next step.
var express = require('express');
var router = express.Router();
const { getMoviesBygenre,getMovies } = require('../controllers/movieController')
/* GET movie listing. */
router.get('/', getMovies);
/* GET movies for imdb and save them in the database. */
router.post('/updateMoviesByGenre',getMoviesBygenre);
module.exports = router;We have two functions the first one is to get all the movies and we will add a filter to search the movies router.get('/', getMovies);
The second function is for scrapping the data from the IMDB website router.post('/updateMoviesByGenre',getMoviesBygenre); .
Let’s create the controller and create the first function getMoviesBygenre.
//import web scraping service
const {getMoviesFromIMDB} = require('../services/movieServices')
exports.getMoviesBygenre = async (req, res) => {
//getting the genre and prepare the url
const {genre } = req.body;
const url = `https://www.imdb.com/search/keyword/?genres=${genre}&title_type=movie&ref_=kw_vw_adv&sort=user_rating,desc&mode=advanced`;
// remove await if you dont want to wait :D
await getMoviesFromIMDB(url);
res.status(200).json({
success:true,
});
}We imported the web scraping service that we will create later but for now, we need to understand the website that we will scrap and should start with the URL.
https://www.imdb.com/search/keyword/?genres=${genre}&title_type=movie&ref_=kw_vw_adv&sort=user_rating,desc&mode=advanced
As you can see the URL has many query URL parameters to filter and get the data you want, I need to get public movies by genre so I found this parameter genres=${genre} and by default, the result is sorted by the IMDb Rating.
you can learn more about the URL by trying to search on the website and observe the changes in the URL to add more filters to your application but for now, we will use the genres.
Let’s create this function getMoviesFromIMDB. create new file services/movieServices.js.
In this function, we have url and page as parameters by default 1, that’s the number of the page to start scrapping.
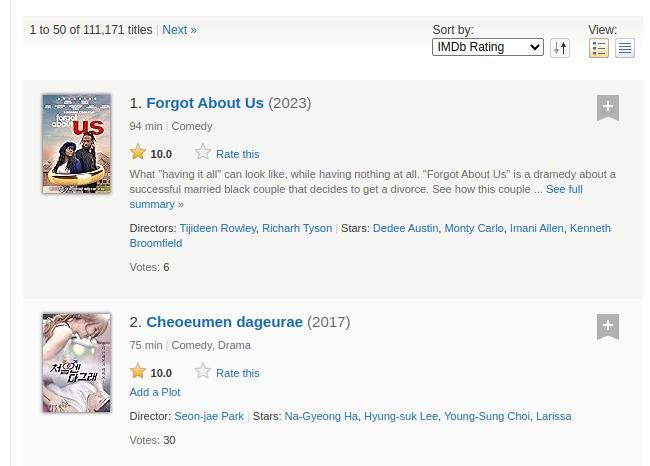
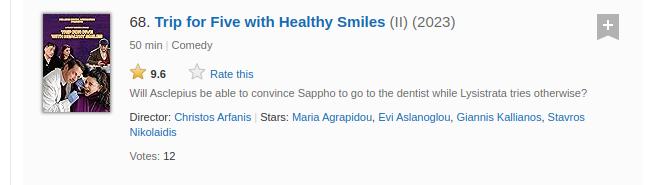
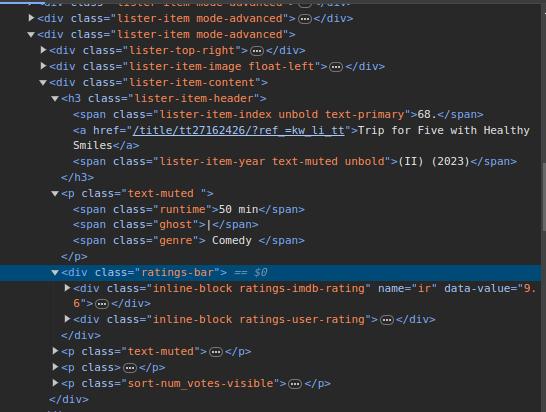
We need to understand carefully the HTML structure of the web page that we will scrap to get the data we want.
const cheerio = require('cheerio');
const axios = require('axios');
const models = require('../models'); // loads index.js
const Movie = models.Movie;
exports.getMoviesFromIMDB = async (url, page = 1) => {
let lastPage = 1;
await axios.get(url+'&page=1').then((response) => {
const $ = cheerio.load(response.data);
lastPage = $(".lister-current-last-item").text()
});
console.log(lastPage);
let limitPages;
lastPage > 3 ? limitPages = 3 : limitPages = lastPage;
while(page <= limitPages){
await axios.get(url+'&page='+page).then((response) => {
const $ = cheerio.load(response.data);
$(".lister-item").each((i, el) => {
const $movie = $(el);
const name = $movie.find("h3>a").text();
const GetPartAndYear = $movie.find(".lister-item-year").text();
let regex = /\(\w+\)/;
let match = GetPartAndYear.match(regex);
const part = match[1];
part? name = `${name} ${part}` : '';
console.log(part);
regex = /\d+/;
match = GetPartAndYear.match(regex);
const year = match[0];
const genre = $movie.find(".genre").text();
const rate = $movie.find(".ratings-imdb-rating strong").text();
const certificate = $movie.find(".certificate").text();
const runtime = $movie.find(".runtime").text().replace(' min','');
const description = $movie.find(".lister-item-content>p:nth-of-type(2)").text();
const cast = $movie.find(".lister-item-content>p:nth-of-type(3)").text();
const vote = $movie.find(".lister-item-content>p:nth-of-type(4)>span:nth-of-type(2)").text();
const gross = $movie.find(".lister-item-content>p:nth-of-type(4)>span:nth-of-type(5)").text();
// console.log(vote,gross,'\n');
//saving the movie in the database
const movie = Movie.findOrCreate({
where: { name: name },
defaults: {
name: name,
year: year,
genre: genre,
rate: rate,
certificate: certificate,
runtime:Number(runtime) ,
description: description,
cast: cast,
vote: !isNaN(Number(vote)) ? Number(vote): null,
gross: gross,
}
});
});
});
page++;
}
console.log('done');
}Let’s explain the code.
let lastPage = 1;we store the last page of the data from the IMDb website here and we will get the last page bylastPage = $(".lister-current-last-item").text().- We used
axiosto get the web page and add the page number to the URL. - We used Cheerio to parse the HTML and extract the text from the elements
const $ = cheerio.load(response.data); -
lastPage > 3 ? limitPages = 3 : limitPages = lastPage;here I limit the maximum pages by 3 pages, you can add more if you want and you can make it as parameter of the function.
After we know how many pages are on “imdb” and by default it’s 50 movies per page we can set our loop to extract the data and save them in our database.
We iterate over each element with class lister-item, which represents a movie. Inside the loop, it extracts various details about the movie:
- Name (from
h3>aelement) - Part (from
lister-item-yearelement using regex) - Year (from
lister-item-yearelement using regex) - Genre (from
.genreelement) - Rating (from
.ratings-imdb-rating strongelement) - Certificate (from
.certificateelement) - Runtime (from
.runtimeelement, removing “min”) - Description (from
.lister-item-content>p:nth-of-type(2)element) - Cast (from
.lister-item-content>p:nth-of-type(3)element) - Vote count (from
.lister-item-content>p:nth-of-type(4)>span:nth-of-type(2)element) - Gross earnings (from
.lister-item-content>p:nth-of-type(4)>span:nth-of-type(5)element)
Finally, we save the movie in the database by the movie model Movie.findOrCreate() and we use the find or create function to not duplicate the movie.
Movie Filter
The final part of our application is the search filter, we will create this function getMovies in controllers/movieController.js
const {getMoviesFromIMDB} = require('../services/movieServices')
const {getResult} = require('../services/getResult')
const {movieFilter} = require('../services/filters/movieFilter')
exports.getMovies = async (req, res) => {
res.status(200).json(await getResult(req,'Movie',movieFilter));
}The function will return movie data as JSON and we use getResult function that takes the request and model name of Sequalize and the allowed filter.
Let’s create services/filters/movieFilter.js file and add an object to contain the column name and type to let the getResult function know what column to search for and filter the data by.
exports.movieFilter = {
name:"String",
genre:"String",
rate:"number"
};Let’s create the function in this file services/getResult.js
const models = require('../models'); // loads index.js
const { Op } = require("sequelize");
exports.getResult = async (req,modelName,allowedFilter, limit = 10) => {
const Model = models[modelName];
let currentPage = Number(req.query.page);
let offset = limit *( currentPage - 1) ;
const filter = {
offset: offset,
limit: limit,
where: {
},
}
for (const key in allowedFilter) {
//get filter name
let fitlerName = req.query[key];
//check if the filter comes with url
if(req.query[key]){
//check filter type
let filterSearch ={ [Op.like]: `%${fitlerName}%`}
if( allowedFilter[key] == 'number'){
filterSearch ={ [Op.eq]: fitlerName}
}
// adding filter to query
filter.where[key] = filterSearch;
}
}
const modelData = await Model.findAll(filter)
const count = await Model.count({where : filter.where})
const totalPages = Math.ceil(count/limit)
const nextPage = currentPage < totalPages ? currentPage + 1 : totalPages // Calculate next page
const previousPage = currentPage > 1 ? currentPage - 1 : 1 // Calculate previous page
return {
success:true,
data: modelData,
currentPage: currentPage,
perPage: limit,
showing:modelData.length,
total:count,
totalPages:totalPages,
nextPage :nextPage,
previousPage: previousPage
}
}
The function will return the result with pagination
Function arguments:
- req: This is the Express request object containing the incoming HTTP request information.
- modelName: This is a string representing the name of the model from which data will be retrieved.
- allowedFilter: This is an object that defines the allowed filter criteria for the model. Each key represents a filter name and its corresponding value represents the data type of that filter.
- limit: (optional) This is the number of results to return in each page. Defaults to 10.
The function iterates over each key in the allowedFilter object and adds to filter.where[key] = filterSearch;
Let’s test our application and make sure you are running the server via npm run dev
Try this URL http://127.0.0.1:3000/movies/updateMoviesByGenre to get the movies from IMDb.
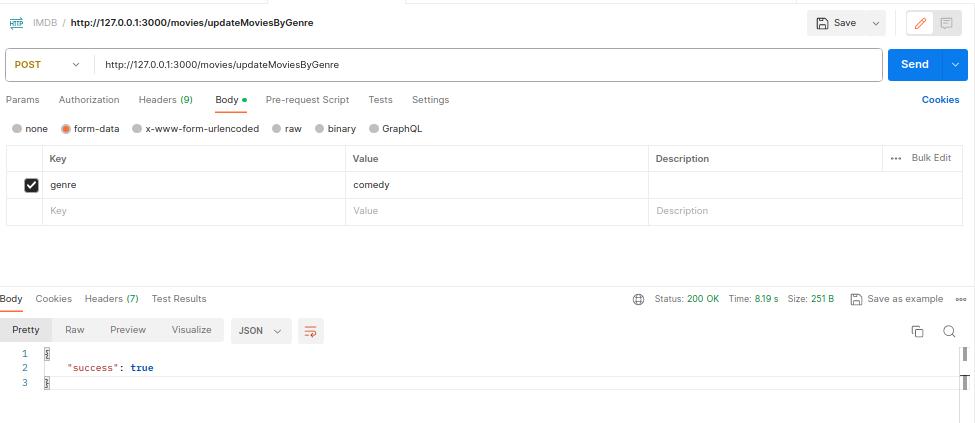
Then try this URL http://127.0.0.1:3000/movies?page=1 to get the movies for your database.
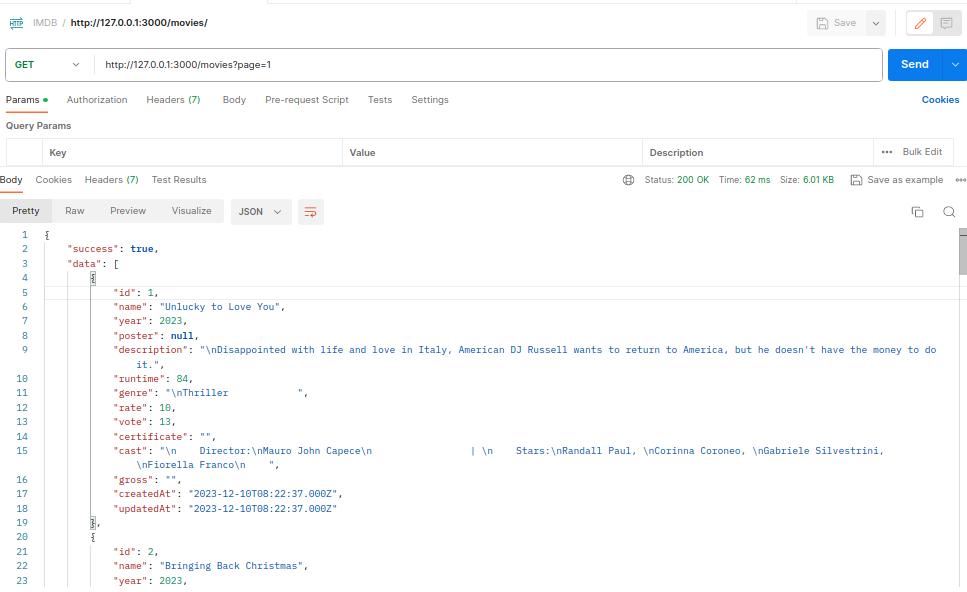
You can optimize and add more features to the application like getting the move posters and cleaning the cast data, you can save the data in MongoDB or as Json in MYSQL there is a lot to do but you get the beginning to do something awesome of yours.
Conclusion
We explained how to make a node.js application with express.js and Sequelize to manage the database as well as understand the web scraping and using Cheerio to parse the HTML, extract the text of the element, and create a search filter that can work with any database model. finally, you can optimize and add more to the code and make it yours. and here is the project link on github.