
{kind=link}
The most significant evolution in modern tech isn’t just the arrival of AI—it’s the shift in where that AI lives. While massive cloud APIs dominate the news, the most resilient systems are moving toward AI Microservices.
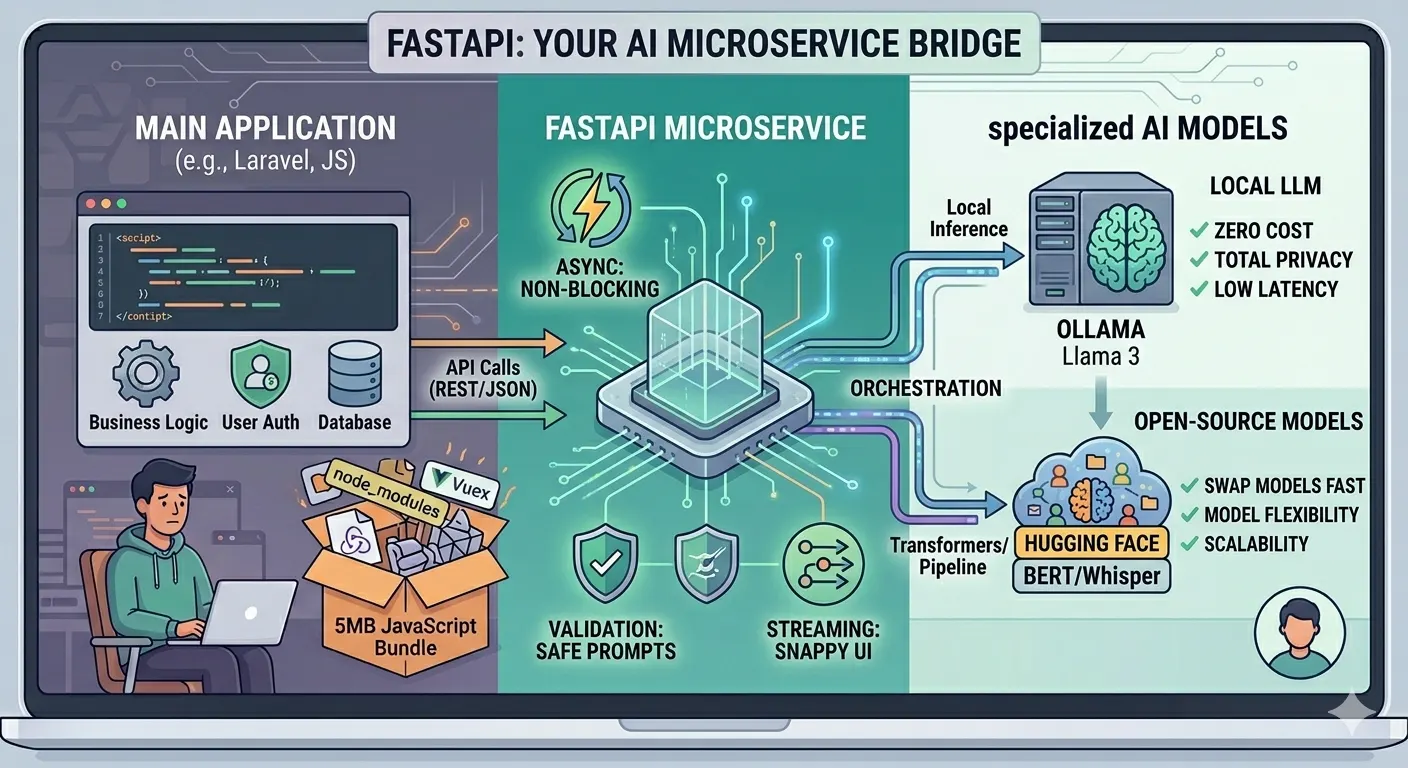
By leveraging FastAPI, you can build a high-performance bridge that connects your primary application to specialized models, whether they are running locally via Ollama or hosted on Hugging Face.
Strategy: Why Architecture Trumps the Model
In a production-grade environment, importing heavy libraries like transformers or torch directly into your main web project is a mistake. This leads to “dependency hell,” creates massive deployment images, and leaves your application vulnerable to memory leaks during intensive inference.
By offloading these tasks to a dedicated FastAPI service, you decouple business logic from machine learning logic. This keeps your main application “thin” and responsive, while the AI service can be isolated on specialized hardware with high-end GPUs. Whether you are prioritizing privacy with a local Ollama LLM or using a Hugging Face model for sentiment analysis, your interface remains a clean, simple API call.
The Microservice Advantage
- Decoupling: Your main application (Laravel, JS, etc.) doesn’t need to manage AI dependencies; it only needs to know a single endpoint URL.
- Cost-Effective Scalability: You can host your FastAPI bridge on GPU-heavy instances while keeping your web server on standard, low-cost hardware.
- Model Agility: Swap a local model for a hosted one in minutes by updating the microservice code—zero changes required for your frontend logic.
The Unified Pattern
This approach creates a single, consistent gateway for your AI needs. Below is a conceptual look at how one service can bridge multiple AI providers seamlessly:
| Feature | Local (Ollama) | Remote (Hugging Face) |
| Privacy | High (Data stays local) | Variable (Cloud-based) |
| Latency | Low (Internal network) | Higher (Internet dependent) |
| Hardware | Requires local GPU/RAM | Managed by provider |
By using this pattern, your infrastructure becomes “model-agnostic,” allowing you to stay flexible as the AI landscape shifts.
This code demonstrates how to handle two different AI providers within a single service.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from langchain_ollama import OllamaLLM
from transformers import pipeline
import asyncio
app = FastAPI(title="AI Microservice Bridge")
# 1. Initialize Models
# Local LLM via Ollama
ollama_model = OllamaLLM(model="llama3")
# Specialized Hugging Face model
sentiment_analyzer = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")
class AIRequest(BaseModel):
prompt: str
task: str = "chat" # chat or sentiment
@app.post("/ai/process")
async def process_ai_task(request: AIRequest):
try:
if request.task == "chat":
# Run in a separate thread to keep FastAPI async loop free
response = await asyncio.to_thread(ollama_model.invoke, request.prompt)
return {"source": "ollama", "result": response}
elif request.task == "sentiment":
result = sentiment_analyzer(request.prompt)
return {"source": "hugging_face", "result": result}
raise HTTPException(status_code=400, detail="Unknown task type")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))